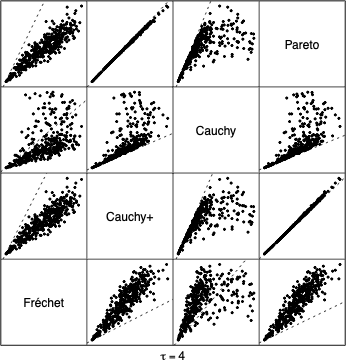
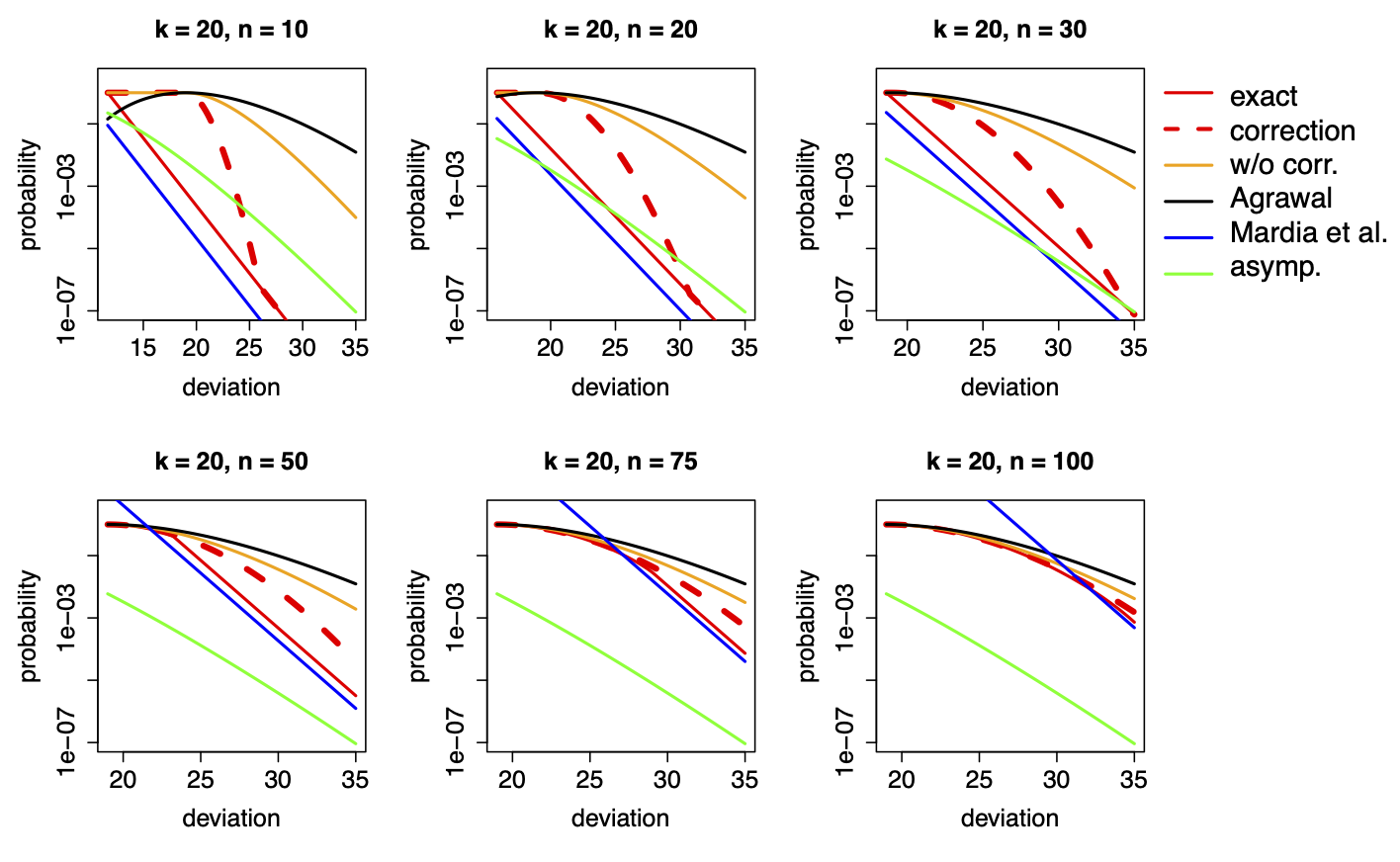
It is often of interest to test a global null hypothesis using multiple, possibly dependent p-values by combining their strengths while controlling the type-I error. Recently, several heavy-tailed combination tests, such as the harmonic mean test and the Cauchy combination test, have been proposed: they transform p-values into heavy-tailed random variables before combining them into a single test statistic. The resulting tests, which are calibrated under some form of independence assumption among the p-values, have been shown to be rather robust to dependence asymptotically as the αlevel gets small. Yet, it has remained an open problem to understand this general phenomenon and characterize how such tests behave under dependence. Using the framework of multivariate regular variation from extreme value theory, we show that for a class of combination tests that are homogeneous, the asymptotic level of the test can be expressed using the angular measure under multivariate regular variation. This measure characterizes the dependence of the transformed heavy-tailed variables in their upper tails, or equivalently, the dependence of the p-values near zero. We use this result to study several tests. The harmonic mean test, which coincides with the Pareto linear combination test, is shown to be universally calibrated regardless of the tail dependence; further, this test is shown to be the only one that achieves universal calibration among all homogeneous heavy-tailed combination tests. In contrast, the Cauchy combination test is shown to be universally honest but often conservative; the Dunn–Šidák correction, also known as the Tippett’s method, while being honest, is calibrated if and only if the underlying p-values are independent near zero. These theoretical findings are corroborated with simulations and an application to independence testing with survey data.